COMPARISION BETWEEN BIOLOGICAL AND ARTIFICIAL NEURAL NETWORKS
BIOLOGICAL VS ARTIFICIAL NEURAL NETWORKS
Artificial neural networks are popular machine learning techniques that simulate the mechanism of learning in biological organisms.
The human nervous system contains cells, which are referred to as neurons.
The neurons are connected to one another with the use of axons and dendrites,
and the connecting regions between axons and dendrites are referred to as synapses.
These connections are displayed in the below picture:
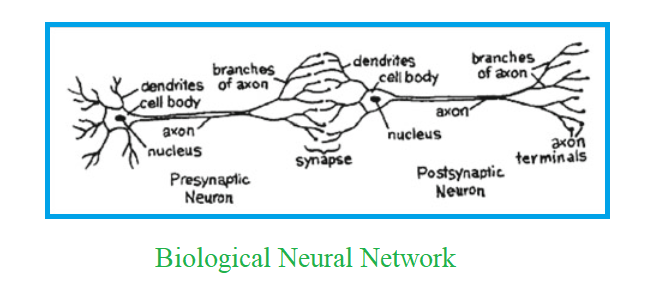
The strengths of synaptic connections often change in response to external stimuli.
This change is how learning takesplace in living organisms.
This biological mechanism is simulated in artificial neural networks, which contain computation units that are referred to as neurons.
In this post, we will use the term "neural networks" to refer to artificial neural networks rather than biological ones.
The computational units are connected to one another through weights, which serve the same role as the strengths of synaptic connections in biological organisms.
Each input to a neuron is scaled with a weight,
which affects the function computed at that unit.
This architecture is displayed in the below image.
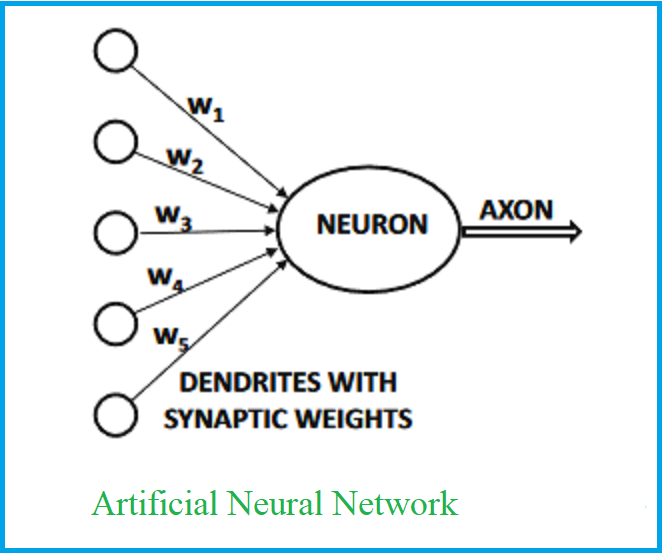
An artificial neural network computes a function of the inputs by propagating the computed values from the input neurons to the output neuron(s)
and using the weights as intermediate parameters. Learning occurs by changing the weights connecting the neurons.
Just as external stimuli are needed for learning in biological organisms,the external stimulus in
artificial neural networks is provided by the training data contain-ing examples of input-output pairs of the function to be learned.
For example, the training data might contain pixel representations of images (input) and their annotated labels
(e.g.,carrot, banana) as the output. These training data pairs are fed into the neural network by using
the input representations to make predictions about the output labels.
The training data provides feedback to the correctness of the weights in the neural network dependingon
how well the predicted output (e.g., probability of carrot) for a particular input matches the annotated output label in the training data.
One can view the errors made by the neural network in the computation of a function as a kind of unpleasant feedback in a biological organism,
leading to an adjustment in the synaptic strengths.
Similarly, the weights between neurons are adjusted in a neural network in response to prediction errors.
The goal of chang-ing the weights is to modify the computed function to make the predictions more correct in future iterations.
Therefore, the weights are changed carefully in a mathematically justifiedway so as to reduce the error in computation on that example.
By successively adjusting the weights between neurons over many input-output pairs,
the function computed by theneural network is refined over time so that it provides more accurate predictions.
Therefore,if the neural network is trained with many different images of bananas,
it will eventually be able to properly recognize a banana in an image it has not seen before.
This ability to accurately compute functions of unseen inputs by training over a finite set of input-output pairs is referred
to as model generalization. The primary usefulness of all machine learning models is gained from their ability to generalize their
learning from seen training data to unseen examples.
The biological comparison is often criticized as a very poor caricature of the workings of the human brain.
nevertheless, the principles of neuroscience have often been useful in designing neural network architectures.
A different view is that neural networks are builtas higher-level abstractions of the classical models that are commonly used in machine learning.
In fact, the most basic units of computation in the neural network are inspired by traditional machine learning algorithms like
least-squares regression and logistic regression.Neural networks gain their power by putting together many such basic units,
and learning the weights of the different units jointly in order to minimize the prediction error.
From this point of view, a neural network can be viewed as a computational graph of elementary units
in which greater power is gained by connecting them in particular ways. When aneural network is used in its most basic form,
without hooking together multiple units, the learning algorithms often reduce to classical machine learning models .
The real power of a neural model over classical methods is unleashed when these elementary computational units are combined,
and the weights of the elementary models are trained using their dependencies on one another.
By combining multiple units,
one is increasing the power of the model to learn more complicated functions of the data than are inherent in the elementary models of basic machine learning.
The way in which these units are combinedalso plays a role in the power of the architecture,
and requires some understanding and insight from the analyst. Furthermore,
sufficient training data is also required in order to learn the larger number of weights in these expanded computational graphs.
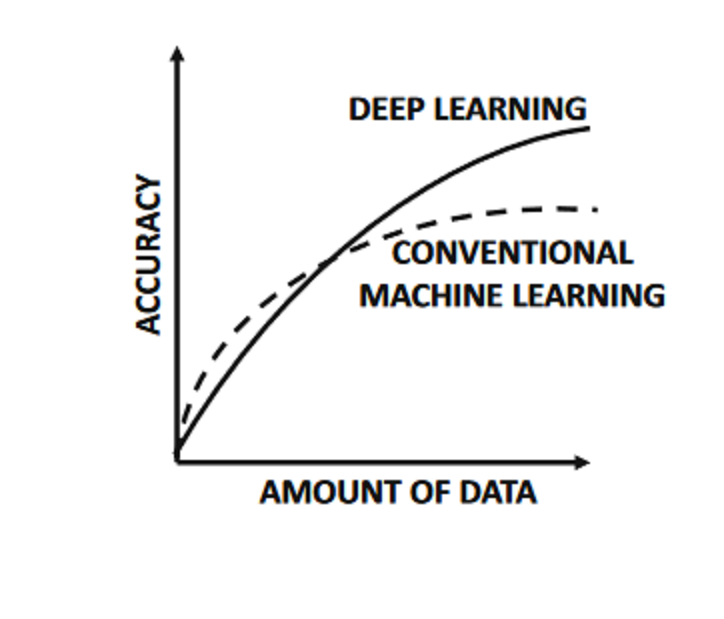
An graphical comparison of the accuracy of a typical machine learning algorithm with that of a large neural network.
Deep learners become more attractive than conventional methods primarily when sufficient data and computational power is available.
Recent years have seen an increase in data availability and computational power, which has led to a "Cambrian explosion" in deep learning technology.